Post Syndicated from Jodi Scrofani original https://aws.amazon.com/blogs/security/compliance-in-the-cloud-for-new-financial-services-cybersecurity-regulations/
Financial regulatory agencies are focused more than ever on ensuring responsible innovation. Consequently, if you want to achieve compliance with financial services regulations, you must be increasingly agile and employ dynamic security capabilities. AWS enables you to achieve this by providing you with the tools you need to scale your security and compliance capabilities on AWS.
The following breakdown of the most recent cybersecurity regulations, NY DFS Rule 23 NYCRR 500, demonstrate how AWS continues to focus on your regulatory needs in the financial services sector.
Cybersecurity Program, Policy, and CISO (Section 500.02-500.04)
You can use AWS Cloud Compliance to understand the robust controls AWS uses to maintain security and data protection in the cloud. Because your systems are built on top of the AWS Cloud infrastructure, compliance responsibilities are shared. AWS uses whitepapers, reports, certifications, accreditations, and other third-party attestations to provide you with the information you need to understand how AWS manages the security program. To learn more, read an Overview of Risk and Compliance for AWS.
Penetration Testing and Vulnerability Assessments (Section 500.05)
Because security in the AWS Cloud is shared, both you and AWS are responsible for performing penetration testing and vulnerability assessments. You can read about how AWS performs its own testing and assessments in the Overview of Security Processes whitepaper.
Penetration testing and other simulated events are frequently indistinguishable from actual events. AWS has established a policy for you to request permission to conduct penetration tests and vulnerability scans to or originating from the AWS environment. To learn more, see AWS Simulated Event Testing.
Audit Trail (Section 500.06)
AWS CloudTrail is a web service that records AWS API calls associated with your account, including information such as the identity of the API caller, the time of the API call, the source IP address of the API caller, the request parameters, and the response elements returned by the AWS service.
CloudTrail stores this information in log files, which you can access from the AWS Management Console, AWS SDKs, command line tools, and higher-level AWS services such as AWS CloudFormation. You can use the log files to perform security analysis, resource change tracking, and compliance auditing. See the AWS CloudTrail website to learn more, and remember to turn on logging! If you need even more help, you can use one of our AWS Security Partner Solutions.
Access Privileges (Section 500.07)
AWS Identity and Access Management (IAM) enables you to securely control access to AWS services and resources for your users. Using IAM, you can create and manage AWS users and groups, and use permissions to allow and deny access to AWS resources. IAM is a feature of your AWS account offered at no additional charge. To get started using IAM or if you have already registered with AWS, go to the IAM console and get started with IAM best practices.
Application Security (section 500.08)
Moving IT infrastructure to AWS services creates a model of shared responsibility between you and AWS. AWS operates, manages, and controls the components from the host operating system and virtualization layer down to the physical security of the facilities in which the service operates. You assume responsibility and management of the guest operating system (including updates and security patches), other associated application software, and the configuration of the AWS-provided security group firewall. You should carefully consider the services you choose because your responsibilities vary depending on the services used, your integration of those services into your IT environment, and applicable laws and regulations. It is possible for you to enhance security or meet your more stringent compliance requirements by leveraging technology such as host-based firewalls, host-based intrusion detection and prevention, encryption, and key management. The nature of this shared responsibility also provides the flexibility and control that permits the deployment of solutions that meet industry-specific certification requirements.
The AWS system development lifecycle incorporates industry best practices that include formal design reviews by the AWS Security Team, threat modeling, and completion of a risk assessment. See the AWS Overview of Security Processes for further details.
Risk Assessment (Section 500.09)
AWS management has developed a strategic business plan that includes risk identification and the implementation of controls to mitigate or manage risks. AWS management reevaluates the strategic business plan at least biannually. This process requires management to identify risks within its areas of responsibility and to implement appropriate measures designed to address those risks.
In addition, the AWS control environment is subject to various internal and external risk assessments. AWS Compliance and Security teams have established an information security framework and policies that are based on the Control Objectives for Information and Related Technology (COBIT) framework and have effectively integrated the ISO 27001 certifiable framework based on ISO 27002 controls, American Institute of Certified Public Accountants (AICPA) Trust Services Principles, the PCI DSS v3.1, and the National Institute of Standards and Technology (NIST) Publication 800-53 Rev 3 (Recommended Security Controls for Federal Information Systems). AWS maintains the security policy, provides security training to employees, and performs application security reviews. These reviews assess the confidentiality, integrity, and availability of data, as well as conformance to the information security policy.
Finally, AWS publishes independent auditor reports and certifications to provide you with considerable information regarding the policies, processes, and controls established and operated by AWS. AWS can provide the relevant certifications and reports to you. Continuous monitoring of logical controls can be executed by you on your own systems. See the AWS Compliance Center for more information about the Assurance Program.
Cybersecurity Personnel and Intelligence (Section 500.10)
AWS manages a comprehensive control environment that includes policies, processes, and control activities that leverage various aspects of the overall Amazon control environment. This control environment is in place for the secure delivery of AWS service offerings. The collective control environment encompasses the people, processes, and technology necessary to establish and maintain an environment that supports the operating effectiveness of the AWS control framework. AWS has integrated applicable cloud-specific controls identified by leading cloud computing industry bodies into the AWS control framework, and AWS continues to monitor these industry groups for ideas on which leading practices can be implemented to better assist you with managing your control environment.
The control environment at Amazon begins at the highest level of the company. Executive and senior leadership play important roles in establishing the company’s tone and core values. Every employee is provided with the company’s Code of Business Conduct and Ethics and completes periodic training. Compliance audits are performed so that employees understand and follow the established policies.
The AWS organizational structure provides a framework for planning, executing and controlling business operations. The organizational structure assigns roles and responsibilities to provide for adequate staffing, the efficiency of operations, and the segregation of duties. Management has also established authority and appropriate lines of reporting for key personnel. Included as part of the company’s hiring verification processes are education, previous employment, and, in some cases, background checks as permitted by law and regulation for employees commensurate with the employee’s position and level of access to AWS facilities. The company follows a structured onboarding process to familiarize new employees with Amazon tools, processes, systems, policies, and procedures.
Third-Party Information Security Policy (Section 500.11)
You have the option to enroll in an Enterprise Agreement with AWS. Using Enterprise Agreements, you can tailor agreements so that they best suit your needs. For more information, contact your sales representative.
Multi-Factor Authentication (Section 500.12)
AWS Multi-Factor Authentication (MFA) is a simple best practice that adds an extra layer of protection on top of your user name and password. With MFA enabled, when users signs in to an AWS website, they will be prompted for their user name and password (the first factor—what they know), as well as for an authentication code from their AWS MFA device (the second factor—what they have). Taken together, these multiple factors provide increased security for your AWS account settings and resources. You can enable MFA for your AWS account and for individual IAM users you have created under your account. MFA can be also be used to control access to AWS service APIs. After you have obtained a supported hardware or virtual MFA device, AWS does not charge any additional fees for using MFA.
You can also protect cross-account access using MFA.
Limitation on Data Retention (Section 500.13)
AWS provides you with the ability to delete their data. However, you retain control and ownership of your data, so it is your responsibility to manage data retention to your own requirements. See AWS Cloud Security Whitepaper for more details.
Training and Monitoring (Section 500.14)
AWS publishes independent auditor reports and certifications to provide you with information about the policies, processes, and controls established and operated by AWS. We can provide the relevant certifications and reports to you. You can execute continuous monitoring of logical controls on your own systems.
For example, Amazon CloudWatch is a web service that provides monitoring for AWS Cloud resources, starting with Amazon EC2. It provides you with visibility into resource utilization, operational performance, and overall demand patterns including metrics such as CPU utilization, disk reads and writes, and network traffic. You can set up CloudWatch alarms to notify you if certain thresholds are crossed or to take other automated actions such as adding or removing EC2 instances if Auto Scaling is enabled.
Encryption of Nonpublic Information (Section 500.15)
You can use your own encryption mechanisms for nearly all AWS services, including Amazon S3, Amazon EBS, Amazon SimpleDB, and Amazon EC2. Amazon VPC sessions are also encrypted. Optionally, you can enable server-side encryption on S3. You can also use third-party encryption technologies. Learn more about AWS KMS and feel free to bring your own keys.
AWS produces, controls, and distributes symmetric cryptographic keys using NIST-approved key management technology and processes in the AWS information system. AWS developed a secure key and credential manager to create, protect, and distribute symmetric keys. The key manager also secures and distributes AWS credentials that are needed on hosts, RSA public/private keys, and X.509 Certifications. AWS cryptographic processes are reviewed by independent third-party auditors for our continued compliance with SOC, PCI DSS, ISO 27001, and FedRAMP.
Incident Response Plan (Section 500.16)
AWS Support is a one-on-one, fast-response support channel that is staffed 24 x 7 x 365 with experienced technical support engineers. The service helps you, regardless of your size or technical ability, to use AWS products and features successfully. AWS provides different tiers of support, which give you the flexibility to choose the support tier that best meets your needs. All AWS Support tiers offer an unlimited number of support cases with pay-by-the-month pricing and no long-term contracts. See Enterprise Support for more information.
Internally, the Amazon Incident Management team employs industry-standard diagnostic procedures to drive resolution during business-impacting events. Staff operators provide 24 x 7 x 365 coverage to detect incidents and manage the impact and resolution. The AWS incident response program, plans, and procedures have been developed in alignment with the ISO 27001 standard. The AWS SOC 1 Type 2 report provides details about the specific control activities that AWS executes.
Contact your sales representative to have our AWS team members help you get started. Don’t have a sales representative yet? Contact us.
– Jodi
 Despite the availability of many legal services, piracy remains rampant througout the United States.
Despite the availability of many legal services, piracy remains rampant througout the United States.
























































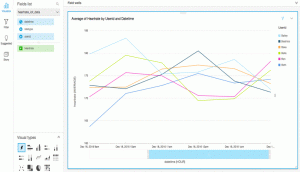
 Suresh Akena is a Senior Big data/IT Transformation architect for AWS Professional Services. He works with the enterprise customers to provide leadership on large scale data strategies including migration to AWS platform, big data and analytics projects and help them to optimize and improve time to market for data driven applications when using AWS. In his spare time, he likes to play with his 8 and 3 year old daughters and watch movies.
Suresh Akena is a Senior Big data/IT Transformation architect for AWS Professional Services. He works with the enterprise customers to provide leadership on large scale data strategies including migration to AWS platform, big data and analytics projects and help them to optimize and improve time to market for data driven applications when using AWS. In his spare time, he likes to play with his 8 and 3 year old daughters and watch movies.





























 Sai Sriparasa is a Big Data Consultant for AWS Professional Services. He works with our customers to provide strategic & tactical big data solutions with an emphasis on automation, operations & security on AWS. In his spare time, he follows sports and current affairs.
Sai Sriparasa is a Big Data Consultant for AWS Professional Services. He works with our customers to provide strategic & tactical big data solutions with an emphasis on automation, operations & security on AWS. In his spare time, he follows sports and current affairs.





 Millions of people use Kodi as their main source of entertainment, often with help from add-ons that allow them to access pirated movies and TV-shows.
Millions of people use Kodi as their main source of entertainment, often with help from add-ons that allow them to access pirated movies and TV-shows. 
 Neil Mukerje is a Solutions Architect with AWS. He guides customers on AWS architecture and best practices. In his spare time, he ponders on the cosmic significance of everything he does.
Neil Mukerje is a Solutions Architect with AWS. He guides customers on AWS architecture and best practices. In his spare time, he ponders on the cosmic significance of everything he does.