Post Syndicated from Eric Fitzgerald original https://aws.amazon.com/blogs/security/how-to-remediate-amazon-inspector-security-findings-automatically/
The Amazon Inspector security assessment service can evaluate the operating environments and applications you have deployed on AWS for common and emerging security vulnerabilities automatically. As an AWS-built service, Amazon Inspector is designed to exchange data and interact with other core AWS services not only to identify potential security findings, but also to automate addressing those findings.
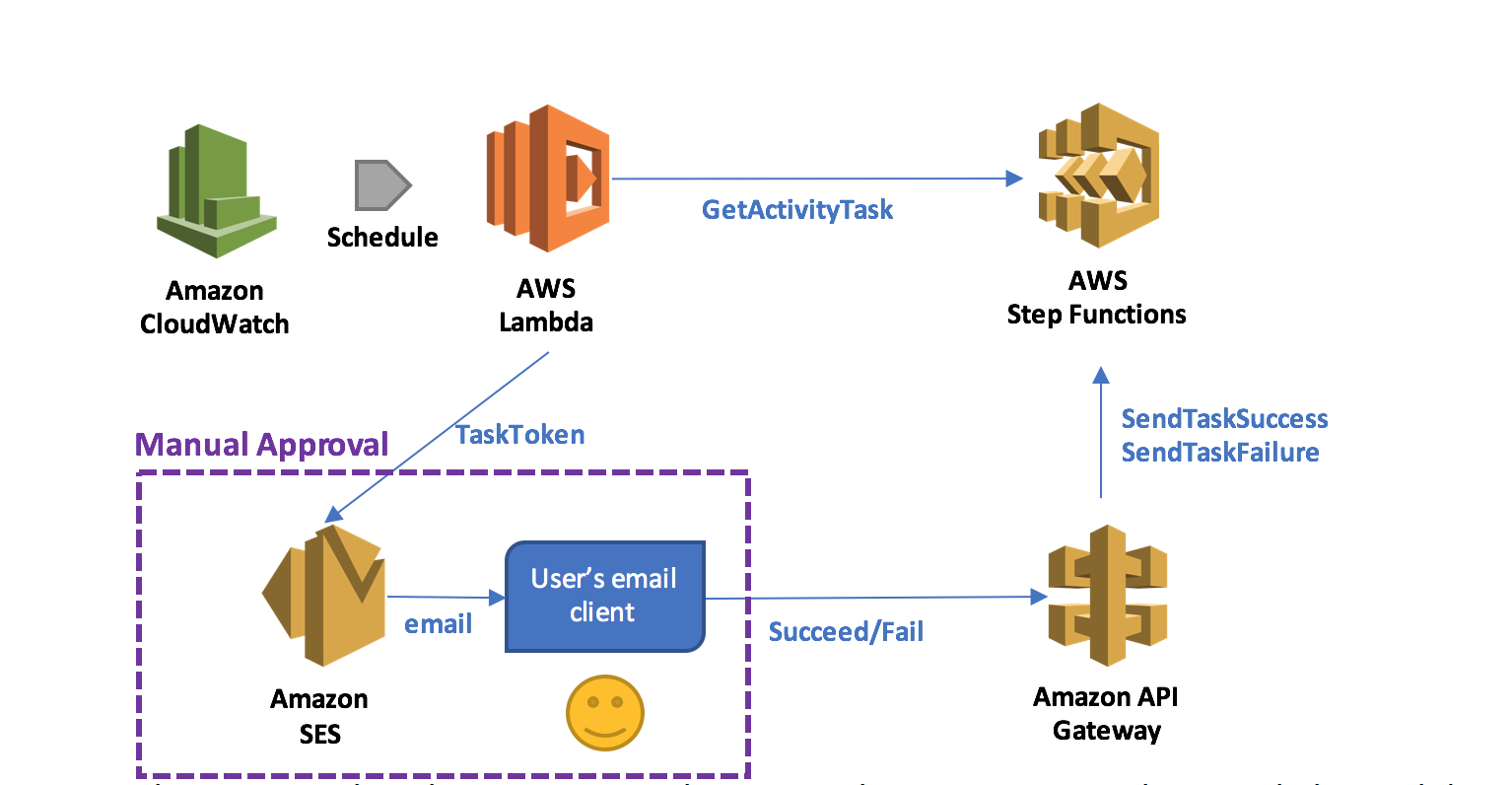
Previous related blog posts showed how you can deliver Amazon Inspector security findings automatically to third-party ticketing systems and automate the installation of the Amazon Inspector agent on new Amazon EC2 instances. In this post, I show how you can automatically remediate findings generated by Amazon Inspector. To get started, you must first run an assessment and publish any security findings to an Amazon Simple Notification Service (SNS) topic. Then, you create an AWS Lambda function that is triggered by those notifications. Finally, the Lambda function examines the findings, and then implements the appropriate remediation based on the type of issue.
Use case
In this post’s example, I find a common vulnerability and exposure (CVE) for a missing update and use Lambda to call the Amazon EC2 Systems Manager to update the instance. However, this is just one use case and the underlying logic can be used for multiple cases such as software and application patching, kernel version updates, security permissions and roles changes, and configuration changes.
The solution
Overview
The solution in this blog post does the following:
- Launches a new Amazon EC2 instance, deploying the EC2 Simple Systems Manager (SSM) agent and its role to the instance.
- Deploys the Amazon Inspector agent to the instance by using EC2 Systems Manager.
- Creates an SNS topic to which Amazon Inspector will publish messages.
- Configures an Amazon Inspector assessment template to post finding notifications to the SNS topic.
- Creates the Lambda function that is triggered by notifications to the SNS topic and uses EC2 Systems Manager from within the Lambda function to perform automatic remediation on the instance.
1. Launch an EC2 instance with EC2 Systems Manager enabled
In my previous Security Blog post, I discussed the use of EC2 user data to deploy the EC2 SSM agent to a Linux instance. To enable the type of autoremediation we are talking about, it is necessary to have the EC2 Systems Manager installed on your instances. If you already have EC2 Systems Manager installed on your instances, you can move on to Step 2. Otherwise, let’s take a minute to review how the process works:
- Create an AWS Identity and Access Management (IAM) role so that the on-instance EC2 SSM agent can communicate with EC2 Systems Manager. You can learn more about the process of creating a role while launching an instance.
- While launching the instance with the EC2 launch wizard, associate the role you just created with the new instance and provide the appropriate script as user data for your operating system and architecture to install the EC2 Systems Manager agent as the instance is launched. See the process and scripts.

Note: You must change the scripts slightly when copying them from the instructions to the EC2 user data. The word region in the curl command must be replaced with the AWS region code (for example, us-east-1).
2. Deploy the Amazon Inspector agent to the instance by using EC2 Systems Manager
You can deploy the Amazon Inspector agent with EC2 Systems Manager, with EC2 instance user data, or by connecting to an EC2 instance via SSH and running the installation steps manually. Because you just installed the EC2 SSM agent, you will use that method.
To deploy the Amazon Inspector agent:
- Navigate to the EC2 console in the desired region. In the navigation pane, choose Command History under Commands near the bottom of the list.
- Choose Run a command.
- Choose the AWS-RunShellScript command document, and then choose Select instances to specify the instance that you created previously. Note: If you do not see the instance in that list, you probably did not successfully install the EC2 SSM agent. This means you have to start over with the previous section. Common mistakes include failing to associate a role with the instance, failing to associate the correct policy with the role, or providing an incorrect user data script.
- Paste the following script in the Commands.
- Choose Run to execute the script on the instance.

3. Create an SNS topic to which Amazon Inspector will publish messages
Amazon SNS uses topics, communication channels for sending messages and subscribing to notifications. You will create an SNS topic for this solution to which Amazon Inspector publishes messages whenever there is a security finding. Later, you will create a Lambda function that subscribes to this topic and receives a notification whenever a new security finding is generated.
To create an SNS topic:
- In the AWS Management Console, navigate to the SNS console.
- Choose Create topic. Type a topic name and a display name, and choose Create topic.
- From the list of displayed topics, choose the topic that you just created by selecting the check box to the left of the topic name, and then choose Edit topic policy from the Other topic actions drop-down list.
- In the Advanced view tab, find the Principal section of the policy document. In that section, replace the line that says “AWS”: “*” with the following text: “Service”: “inspector.amazonaws.com” (see the following screenshot).
- Choose Update policy to save the changes.
- Choose Edit topic policy On the Basic view tab, set the topic policy to allow Only me (topic owner) to subscribe to the topic, and choose Update policy to save the changes.

4. Configure an Amazon Inspector assessment template to post finding notifications to the SNS topic
An assessment template is a configuration that tells Amazon Inspector how to construct a specific security evaluation. For example, an assessment template can tell Amazon Inspector which EC2 instances to target and which rules packages to evaluate. You can configure a template to tell Amazon Inspector to generate SNS notifications when findings are identified. In order to enable automatic remediation, you either create a new template or modify an existing template to set up SNS notifications to the SNS topic that you just created.
To enable automatic remediation:
- Sign in to the AWS Management Console and navigate to the Amazon Inspector console.
- Choose Assessment templates in the navigation pane.
- Choose one of your existing Amazon Inspector assessment templates. If you need to create a new Amazon Inspector template, type a name for the template and choose the Common Vulnerabilities and Exposures rules package. Then go back to the list and select the template.
- Expand the template so that you can see all the settings by choosing the right-pointing arrowhead in the row for that template.
- Choose the pencil icon next to the SNS topics.
- Add the SNS topic that you created in the previous section by choosing it from the Select a new topic to notify of events drop-down list (see the following screenshot).
- Choose Save to save your changes.

5. Create the Lambda autoremediation function
Now, create a Lambda function that listens for Amazon Inspector to notify it of new security findings, and then tells the EC2 SSM agent to run the appropriate system update command (apt-get update or yum update) if the finding is for an unpatched CVE vulnerability.
Step 1: Create an IAM role for the Lambda function to send EC2 Systems Manager commands
A Lambda function needs specific permissions to interact with your AWS resources. You provide these permissions in the form of an IAM role, and the role has a policy attached that permits the Lambda function to receive SNS notifications and to send commands to the Amazon Inspector agent via EC2 Systems Manager.
To create the IAM role:
- Sign in to the AWS Management Console, and navigate to the IAM console.
- Choose Roles in the navigation pane, and then choose Create new role.
- Type a name for the role. You should (but are not required to) use a descriptive name such as Amazon Inspector-agent-autodeploy-lambda. Regardless of the name you choose, remember the name because you will need it in the next section.
- Choose the AWS Lambda role type.
- Attach the policies AWSLambdaBasicExecutionRole and AmazonSSMFullAccess.
- Choose Create the role.
Step 2: Create the Lambda function that will update the host by sending the appropriate commands through EC2 Systems Manager
Now, create the Lambda function. You can download the source code for this function from the .zip file link in the following procedure. Some things to note about the function are:
- The function listens for notifications on the configured SNS topic, but only acts on notifications that are from Amazon Inspector that report a finding and are reporting a CVE vulnerability.
- The function checks to ensure that the EC2 SSM agent is installed, running, and healthy on the EC2 instance for which the finding was reported.
- The function checks the operating system of the EC2 instance and determines if it is a supported Linux distribution (Ubuntu or Amazon Linux).
- The function sends the distribution-appropriate package update command (apt-get update or yum update) to the EC2 instance via EC2 Systems Manager.
- The function does not reboot the agent. You either have to add that functionality yourself or reboot the agent manually.
To create the Lambda function:
- Sign in to the AWS Management Console in the region that you intend to use, and navigate to the Lambda console.
- Choose Create a Lambda function.
- On the Select a blueprint page, choose the Hello World Python blueprint and choose Next.
- On the Configure triggers page, choose SNS as the trigger, and choose the SNS topic that you created in the last section. Choose the Enable trigger check box and choose Next.
- Type a name and description for the function. Choose Python 2.7 runtime.
- Download and save this .zip file.
- Unzip the .zip file, and copy the entire contents of lambda-auto-remediate.py to your clipboard.
- Choose Edit code inline under Code entry type in the Lambda function, and replace all the existing text with the text that you just copied from lambda-auto-remediate.py.
- Select Choose an existing role from the Role drop-down list, and then in the Existing role box, choose the IAM role that you created in Step 1 of this section.
- Choose Next and then Create function to complete the creation of the function.
You now have a working system that monitors Amazon Inspector for CVE findings and will patch affected Ubuntu or Amazon Linux instances automatically. You can view or modify the source code for the function in the Lambda console. Additionally, Lambda and EC2 Systems Manager will generate logs whenever the function causes an agent to patch itself.
Note: If you have multiple CVE findings for an instance, the remediation commands might be executed more than once, but the package managers for Linux handle this efficiently. You still have to reboot the instances yourself, but EC2 Systems Manager includes a feature to do that as well.
Summary
Using Amazon Inspector with Lambda allows you to automate certain security tasks. Because Lambda supports Python and JavaScript, development of such automation is similar to automating any other kind of administrative task via scripting. Even better, you can take actions on EC2 instances in response to Amazon Inspector findings by using Lambda to invoke EC2 Systems Manager. This enables you to take instance-specific actions based on issues that Amazon Inspector finds. Combining these capabilities allows you to build event-driven security automation to help better secure your AWS environment in near real time.
If you have comments about this blog post, submit them in the “Comments” section below. If you have questions about implementing the solution in this post, start a new thread on the Amazon Inspector forum.
– Eric











 In recent years many people have accused so-called ‘copyright trolls’ of using dubious tactics and shoddy evidence, to extract cash settlements from alleged movie pirates.
In recent years many people have accused so-called ‘copyright trolls’ of using dubious tactics and shoddy evidence, to extract cash settlements from alleged movie pirates.





























































 December 2014, The Pirate Bay went dark after police
December 2014, The Pirate Bay went dark after police 
 An Organization is a consolidated set of AWS accounts that you manage. Newly-created Organizations offer the ability to implement sophisticated, account-level controls such as Service Control Policies. This allows Organization administrators to manage lists of allowed and blocked AWS API functions and resources that place guard rails on individual accounts. For example, you could give your advanced R&D team access to a wide range of AWS services, and then be a bit more cautious with your mainstream development and test accounts. Or, on the production side, you could allow access only to AWS services that are eligible for
An Organization is a consolidated set of AWS accounts that you manage. Newly-created Organizations offer the ability to implement sophisticated, account-level controls such as Service Control Policies. This allows Organization administrators to manage lists of allowed and blocked AWS API functions and resources that place guard rails on individual accounts. For example, you could give your advanced R&D team access to a wide range of AWS services, and then be a bit more cautious with your mainstream development and test accounts. Or, on the production side, you could allow access only to AWS services that are eligible for 



















